Photo-Realistic Single Image Super Resolution Using a Generative Adversarial Network
12 Oct 2019Abstract
Despite the breakthroughs in accuracy and speed of single image super-resolution using faster and deeper convolutional neural networks, one central problem remains largely unsolved: how do we recover the finer texture details when we super-resolve at large upscaling factors? The behavior of optimization-based super-resolution methods is principally driven by the choice of the objective function. Recent work has largely focused on minimizing the mean squared reconstruction error. The resulting estimates have high peak signal-to-noise ratios, but they are often lacking high-frequency details and are perceptually unsatisfying in the sense that they fail to match the fidelity expected at the higher resolution. In this paper, we present SRGAN, a generative adversarial network (GAN) for image super-resolution (SR). To our knowledge, it is the first framework capable of inferring photo-realistic natural images for 4× upscaling factors. To achieve this, we propose a perceptual loss function which consists of an adversarial loss and a content loss. The adversarial loss pushes our solution to the natural image manifold using a discriminator network that is trained to differentiate between the super-resolved images and original photo-realistic images. In addition, we use a content loss motivated by perceptual similarity instead of similarity in pixel space. Our deep residual network is able to recover photo-realistic textures from heavily downsampled images on public benchmarks. An extensive mean-opinion-score (MOS) test shows hugely significant gains in perceptual quality using SRGAN. The MOS scores obtained with SRGAN are closer to those of the original high-resolution images than to those obtained with any state-of-the-art method.
깊은 cnn을 활용하여 SR의 도메인에서 좋은 결과를 만들어내고 있지만, 큰 upscaling factor를 사용할 때 디테일한 부분을 어떻게 잡아낼 것인가에 대한 문제가 해결되지 않고 있다.
최적화에 기반한 SR은 목적함수가 핵심이다.
최근 연구는 mean squared reconstruction error(per-pixel error같음)을 최소화 시키는 방향으로 나아가고 있다.
이를 통해 얻어진 결과는 노이즈는 잘 잡아내지만 디테일한 부분이 부족하다는 게 매우 만족스럽지 못하다.
이 논문은 GAN을 활용한 SRGAN을 소개한다.
4배의 upscaling factor를 사용하여 진짜 같은 이미지를 만들어내는 것에선 첫 번째 프레임워크이다.
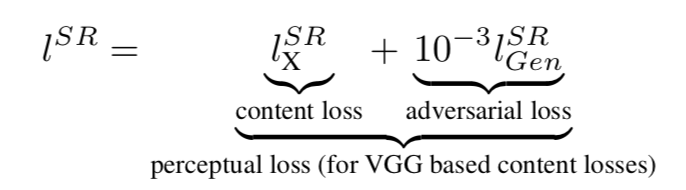
이를 위해 우리는 adversarial, content loss로 우리어진 perceptual loss 함수를 제안한다.
adversarial loss는 진짜 이미지와 sr 이미지의 차이를 학습한 discriminator를 사용하여 자연스러운 이미지를 만들도록 도와준다.
content loss는 픽셀 공간의 유사성이 아닌 feature map(perceltual loss의 특징)의 유사성을 고려한다.
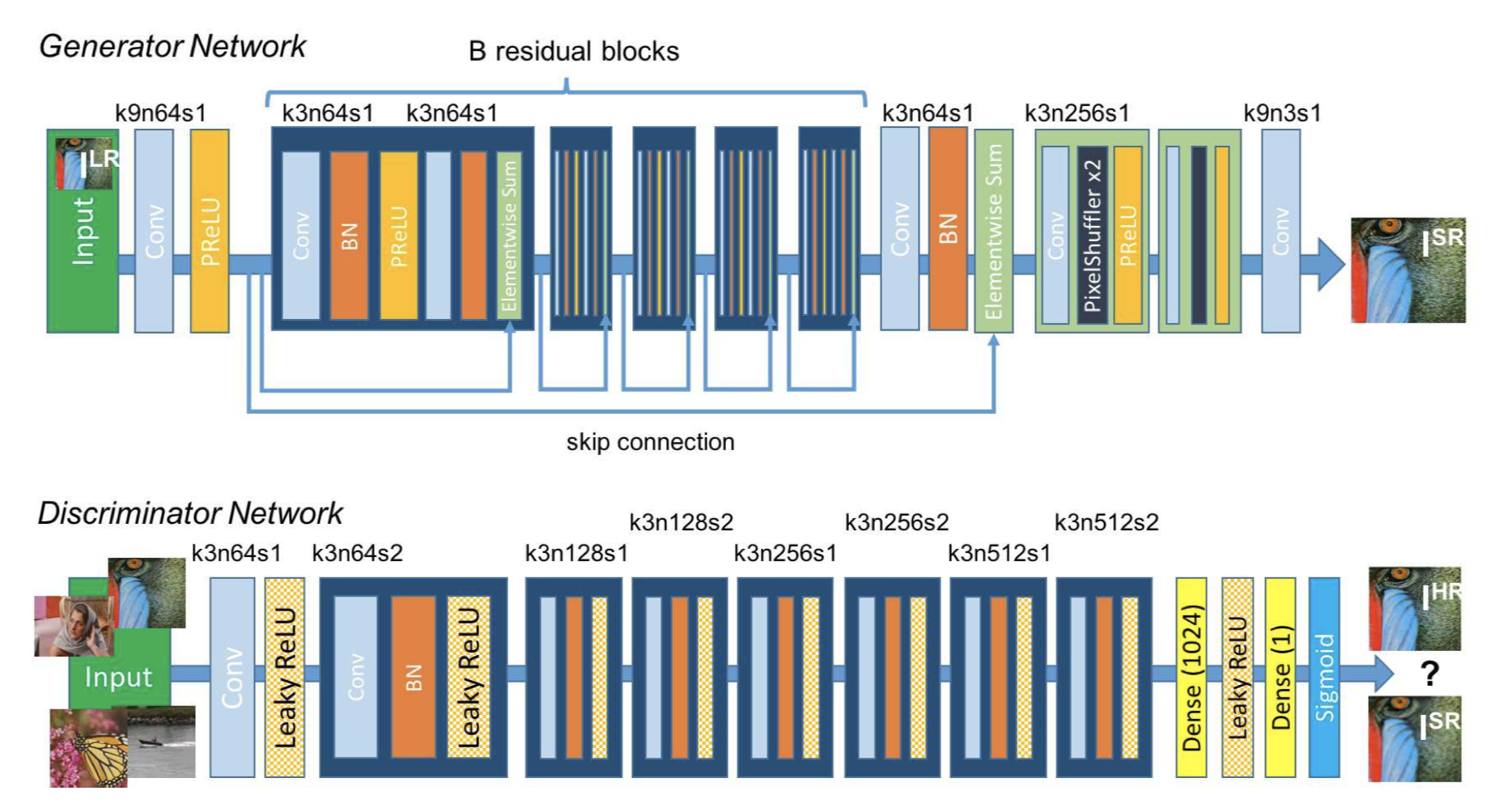
우리가 사용한 깊은 resnet은 다운샘플된 이미지를 진짜 같은 이미지로 복원할 수 있게한다.
SRGAN을 사용함에 따라 MOS에서 유의한 향상을 보였다.
SRGAN과 MOS를 사용하면 더 좋은 결과를 만들어낼 수 있다.
- 이 논문은 진짜 같은 Super-Resolution을 생성하는게 목적이며, 기존에 SR은 여러 장의 이미지를 활용했다는 것에 반해 GAN을 이용하여 한장의 이미지로 결과물을 생성한다.
- 기존의 per-pixel loss는 perceptual difference를 잡아내지 못하기 때문에, 이 논문 또한 perceptual loss를 활용한다.
- Per-pixel MSE는 평균을 사용하기 때문에 디테일이 사라지게 되는 원인이다. 하지만 GAN을 사용하면 이를 보완할 수 있다. GAN은 sampling을 활용하기 때문인데, 이때 sampling된 이미지는 우리가 볼때는 괜찮지만 score 측면에서는 떨어지는 결과를 준다.
- loss를 보면 VGG 네트워크를 사용했다고 나오는데, 이는 GAN 내부에 존재하는 것이 아니라 generator가 뽑아낸 target 값을 단순하게 ‘imagenet weight’가 load된 VGG를 사용하여 feature map을 도출하고, 이를 통해 loss를 계산하는 것이다. 여기서 VGG는 따로 학습되지 않는다.