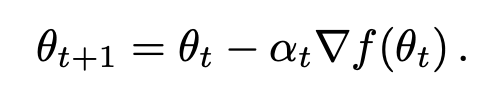Learning to learn by gradient descent by gradient descent
28 Oct 2019Abstract
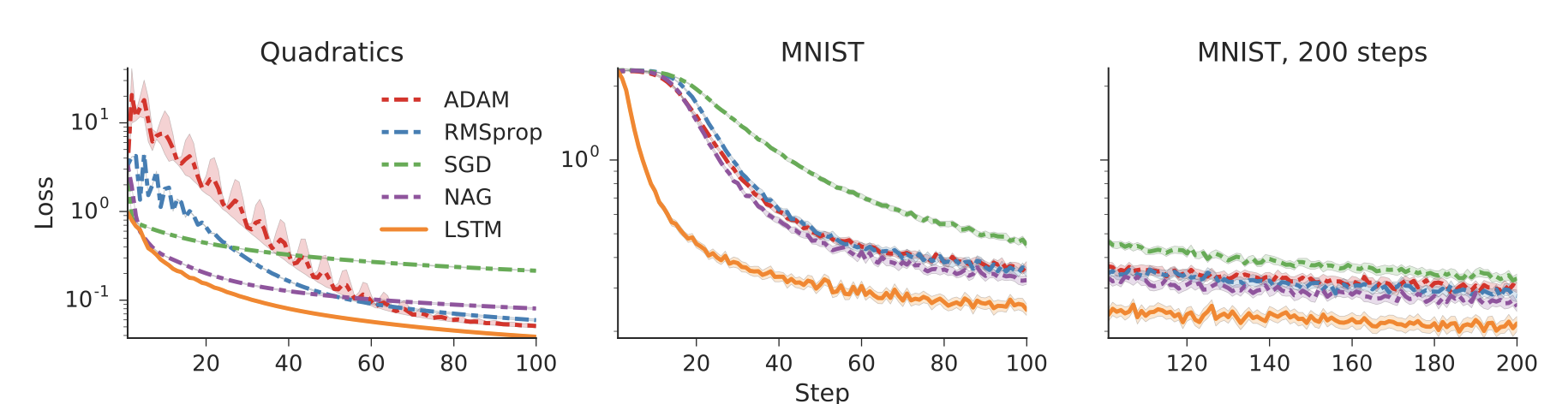
The move from hand-designed features to learned features in machine learning has been wildly successful. In spite of this, optimization algorithms are still designed by hand. In this paper we show how the design of an optimization algorithm can be cast as a learning problem, allowing the algorithm to learn to exploit structure in the problems of interest in an automatic way. Our learned algorithms, implemented by LSTMs, outperform generic, hand-designed competitors on the tasks for which they are trained, and also generalize well to new tasks with similar structure. We demonstrate this on a number of tasks, including simple convex problems, training neural networks, and styling images with neural art.
머신러닝으로 학습된 특징을 사용하는 작업은 매우 성공적이었다.
이와 같은 성공에도 불구하고 최적화 알고리즘은 여전히 직접 설계되어지고 있다.
이 논문은 최적화 알고리즘의 설계를 학습 문제로 정의하여 이를 문제에 맞게 자동으로 설계하게끔 하는 방법을 소개한다.
LSTM으로 구현된 이 알고리즘은 일반적인 최적화 알고리즘의 성능을 뛰어넘으며, 여러 문제에도 일반화될 수 있음을 보여주었다.
우리는 neural art, 신경망 학습, 간단한 convex 문제를 포함한 여러 문제에 이 알고리즘을 적용하였다.
- Learning to learn은 Meta Learning이라고도 한다.
- 일반적으로 밑의 첫번째 그림과 같은 업데이트 방식을 사용하여 학습을 진행하는데, 이는 모든 문제에 일반화기 애매한 수식이다. 따라서 이 논문은 좀 더 일반화할 수 있는 최적화 알고리즘을 얻길 원한다.
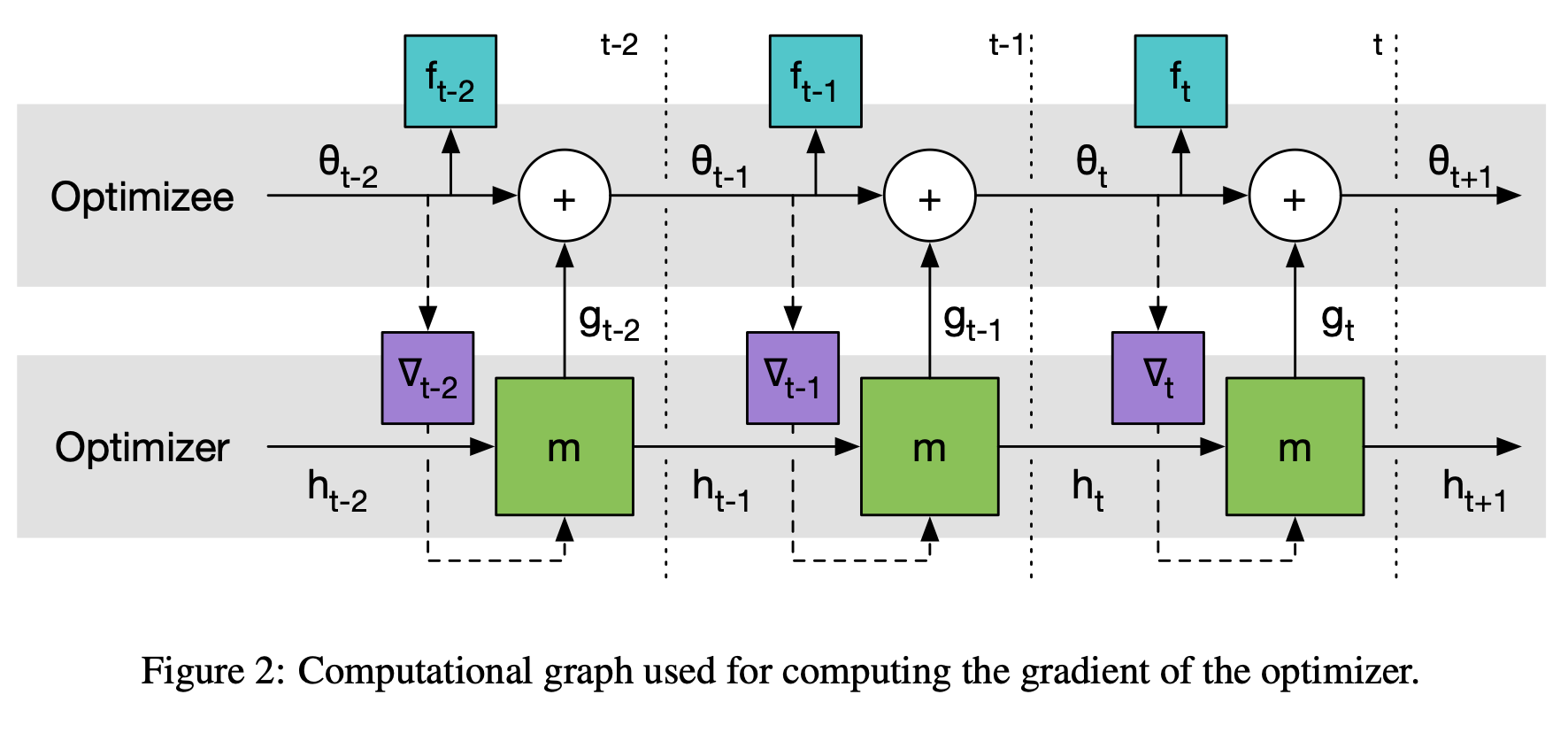
- loss function은 매우 간단하게 구성되어 있으며, 이에 존재하는 f를 optimizee라고 부른다.
- 컴퓨팅 비용을 고려하여 RNN 대신 LSTM을 택하였다.
- 3번째 그림의 dashed line은 f_t의 second order derivative를 구하지 않으려고 한 부분이다.
- 히든 레이어의 유닛 수를 늘린다던가, 레이어의 수를 늘렸을 떄는 좋은 성능을 보였지만, activation function을 바꾸면 학습이 잘 되지 않는다.