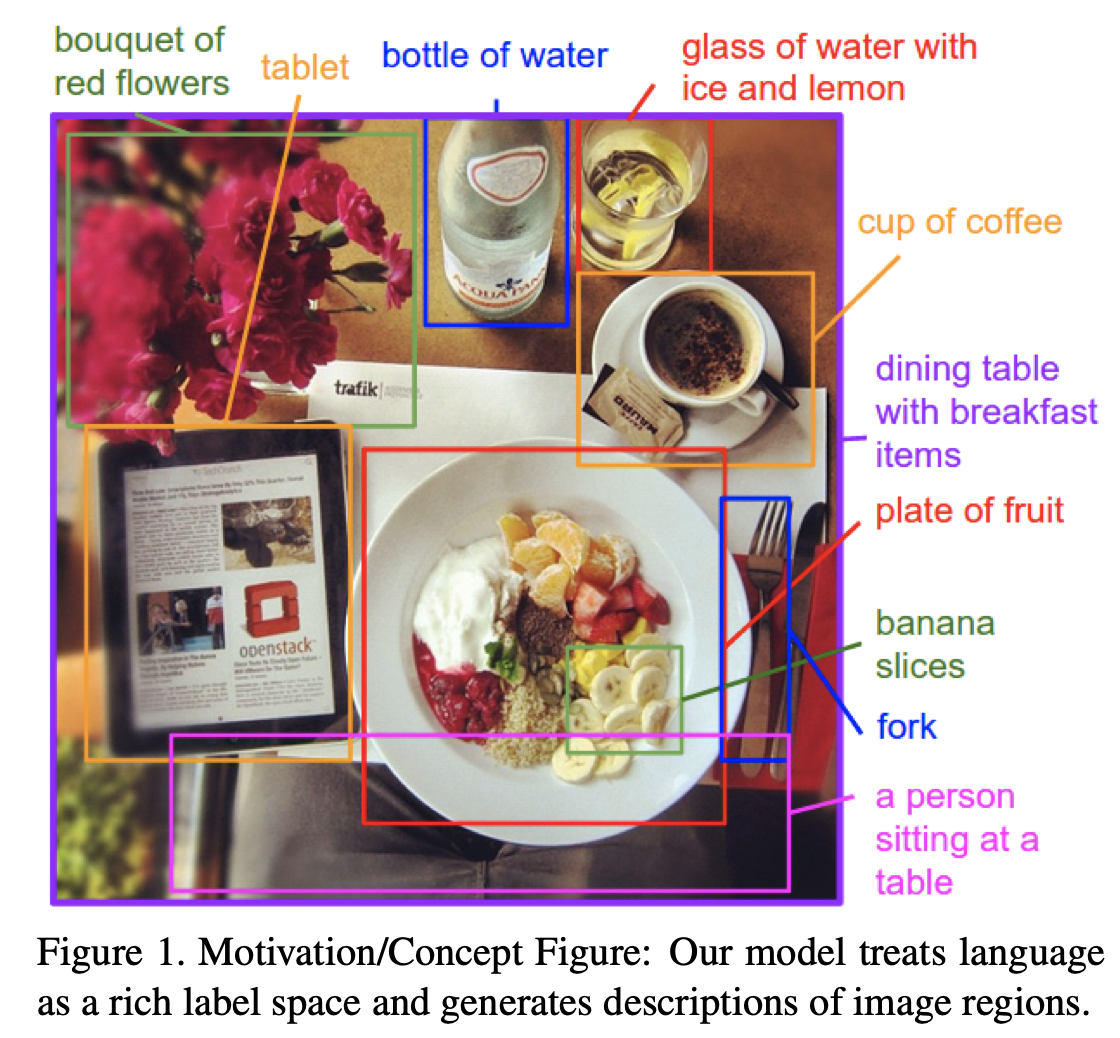
Deep Visual-Semantic Alignments for Generating Image Descriptions
28 Oct 2019Abstract
We present a model that generates natural language descriptions of images and their regions. Our approach leverages datasets of images and their sentence descriptions to learn about the inter-modal correspondences between language and visual data. Our alignment model is based on a novel combination of Convolutional Neural Networks over image regions, bidirectional Recurrent Neural Networks over sentences, and a structured objective that aligns the two modalities through a multimodal embedding. We then describe a Multimodal Recurrent Neural Network architecture that uses the inferred alignments to learn to generate novel descriptions of image regions. We demonstrate that our alignment model produces state of the art results in retrieval experiments on Flickr8K, Flickr30K and MSCOCO datasets. We then show that the generated descriptions significantly outperform retrieval baselines on both full images and on a new dataset of region-level annotations.
이 논문은 각 region과 이미지에 해당하는 캡션을 생성하는 모델을 소개한다.
우리가 제안하는 방법은 이미지 데이터셋과 문장 설명을 활용하여 그 사이의 상호 대응 방식을 학습하는 것이다.
우리의 모델은 이미지 영역에서의 CNN, 문장을 다루는 Bidirectional RNN의 조합에 기반하고, 이를 결합하는 구조화된 목표를 가지고 있다. (multimodal이란 시각 + 언어, 소리 + 언어를 주로 가르키는 것 같음.)
또한, 이미지 영역에 대한 설명을 생성하도록 학습하여 추론된 문장을 사용할 수 있는 Multimodal RNN을 설명한다.
우리는 각종 플리커 데이터셋과 MSCOCO에서의 실험을 통해 최고의 성능을 생성할 수 있음을 증명한다.
더하여서, 새로운 데이터셋의 완전한 이미지를 주었을 때, 이를 설명하는 성능은 매우 우수하다.
- 이미지에 대해 설명을 추가하려는 시도를 하는 첫 번째 논문이다.
- CNN을 사용하여 이미지를 벡터로 임베딩하고, RNN을 통해 단어들을 임베딩한다. 그리고 두 벡터를 통해 연산을 하고 점수를 매긴다.
- Bidirectional RNN을 사용한 이유는 문장 전체의 정보를 사용하기 위함이다.
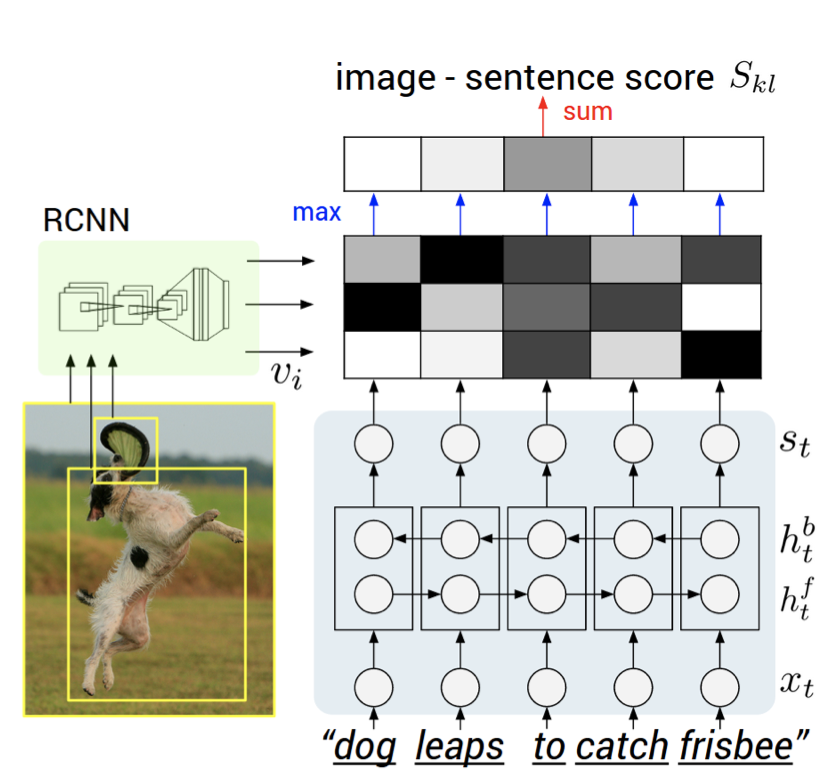
- 결과는 위와 같이 만들어지게 되는데, 각 상자에서 검은색은 가장 확률이 낮은것이고 흰색은 그 반대이다. 이를 통해 점수를 계산한다.
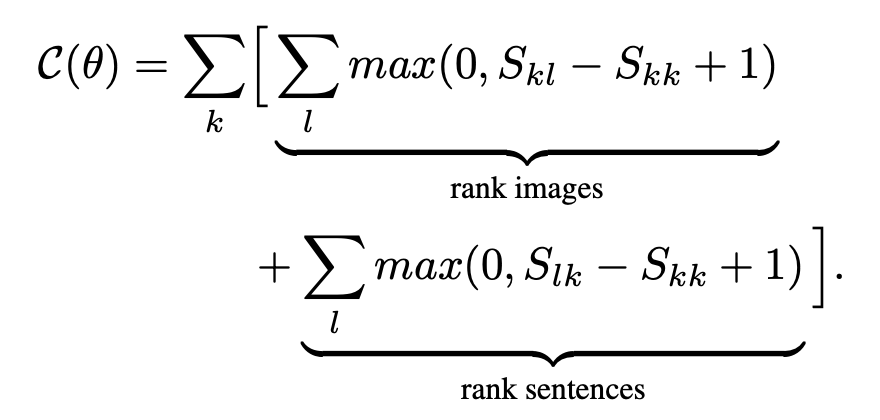
- loss function은 위와 같이 구성되어 있는데, ground_truth(여기서 s_kk)를 뺏을 때의 값을 기준으로 이를 minimize하는 방식이다. max를 이용하여 s_kl이나 s_lk와의 거리를 최대한 좁히려는 것이다.
- 이 함수를 RNN, CNN을 학습시킬 때 사용하였다.
- 에너지 function을 사용하여 이미지와 단어와의 관계가 찢어지는 현상을 해결하려고 했다.
- 마지막으로는 RNN을 사용하여 문장을 생성하려고 했다. 이때, 첫 번째 hidden state에는 가중치를 더해준다.
- 논문에서 R@5, R@10과 같은 수치로 평가하는데, 이는 5번 돌려서 정답이 있을 확률, 10번 돌려서 정답이 있을 확률을 의미한다.