PVANet: Lightweight Deep Neural Networks for Real-time Object Detection
29 Oct 2019Abstract
In object detection, reducing computational cost is as important as improving accuracy for most practical usages. This paper proposes a novel network structure, which is an order of magnitude lighter than other state-of-the-art networks while maintaining the accuracy. Based on the basic principle of more layers with less channels, this new deep neural network minimizes its redundancy by adopting recent innovations including C.ReLU and Inception structure. We also show that this network can be trained efficiently to achieve solid results on well-known object detection benchmarks: 84.9% and 84.2%mAP on VOC2007 and VOC2012 while the required compute is less than 10% of the recent ResNet-101.
객체 탐지에서 계산 비용을 감소시키는 것은 실용적인 측면에서 정확도를 높이는 것만큼 중요하다.
이 논문은 최신 성능을 유지하면서도 더 가벼운 특징을 가지는 신경망 구조를 제안한다.
적은 채널수와 많은 층을 쌓는 기본적인 원리에 기반해서, 인셉션 구조와 C.ReLU를 포함한 가장 최근의 혁신적인 구조의 중복을 최소화한 깊은 신경망이다.
또한, 다음과 같이 각종 데이터셋에서 효율적인 결과를 얻었다. 최근 각광받고 있는 ResNet-101보다 더 가벼운 모델로 VOC2007, VOC2012에서 각각 84.9%, 84.2% mAP를 얻었다.
- 이 논문은 Faster R-CNN의 형태를 개선한 논문이다.
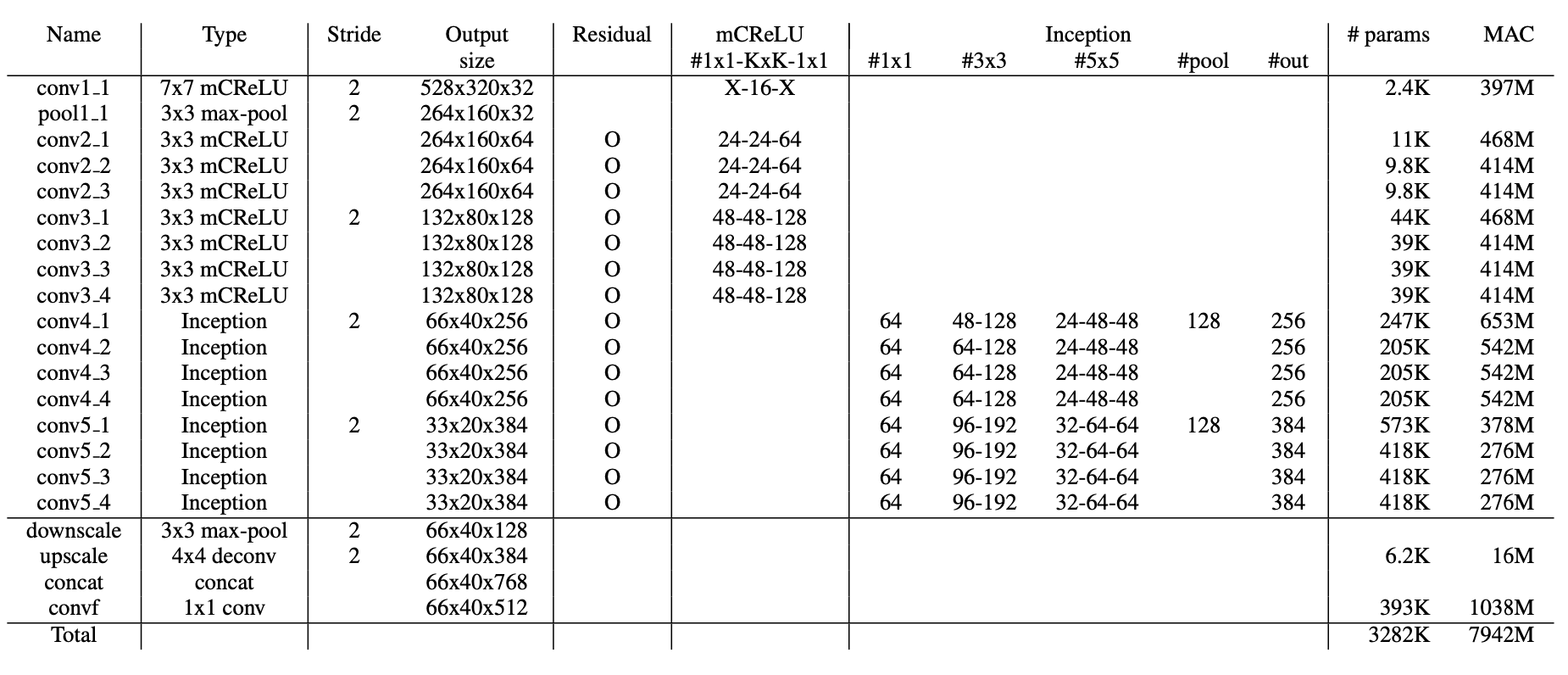
- 네트워크는 깊게 구성하면서도 채널 수는 줄여보자는 취지이다.
- C.ReLU는 기존 방식과 다르게 Scale/Bias를 추가하여 Modified C.ReLU의 형태로 사용하였다.
- Inception 모듈은 그 당시에 객체 탐지에서 잘 사용하지 않았는데, 사용한 이유는 다양한 receptive field를 얻을 수 있을 거라고 생각했기 때문이고, 실제로 사용해보았더니 잘되었다고 한다.
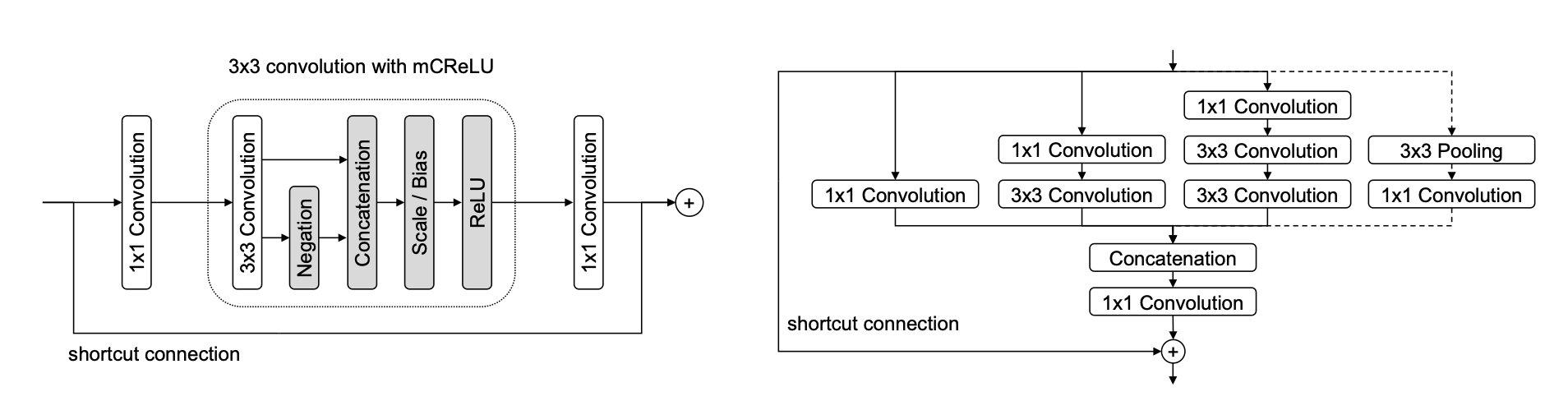
- 또한, skip connection과 구조가 동일한 Hyper-feature Concatenation을 사용하였다. 이때, Upscale할 때는 단순하게 Bilinear interpolation을 사용하였다.
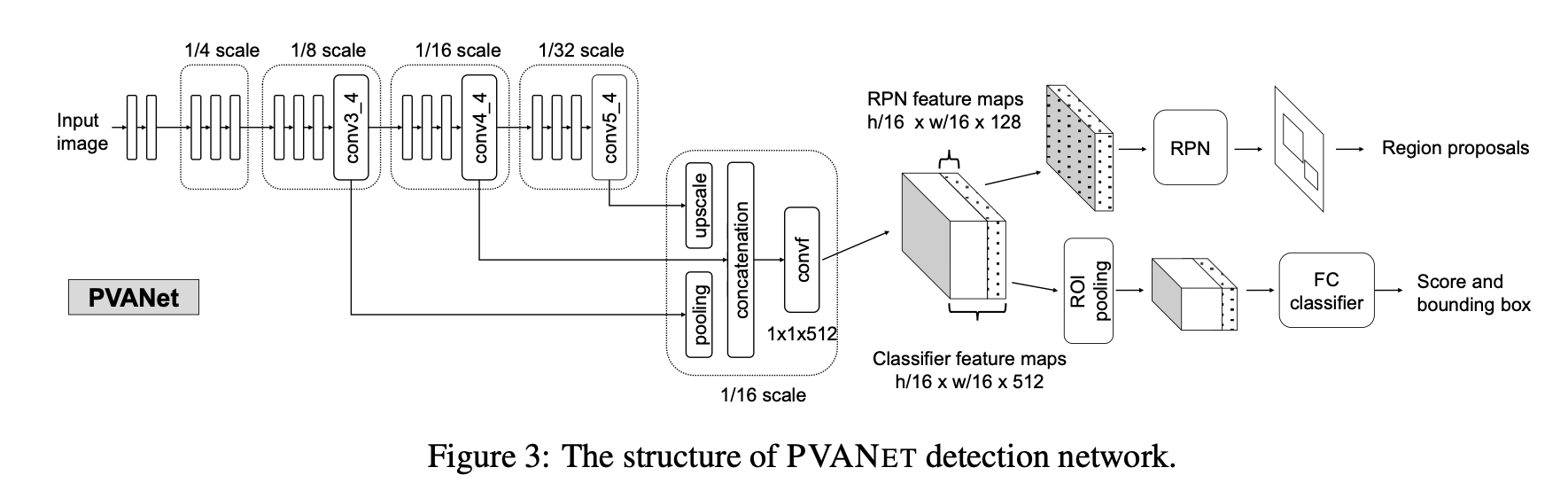
- 이 논문은 RPN시에 최종 출력의 모든 feature를 사용하지 않고 128개의 채널만 떼서 사용한다. 기본적으로 RPN은 객체의 유무만 판단하는 단순한 연산이기 떄문이다. 반대로 분류하는 부분은 모든 채널을 전부 사용한다.