Inside Tensorflow:tf.data
03 Oct 2019이 동영상은 tf.data에 관한 동영상입니다. 본 영상은 여러 언어적 관점에서 다루지만 글은 Python view에서 나오는 내용만 적었습니다.
tf.data
dataset = tf.data.TFRecordDataset(files)
dataset = dataset.shuffle(buffer_size = X)
dataset = dataset.map(lambda record: parse(record))
dataset = dataset.batch(batch_size = Y)
for element in datset:
...
기존 tf 1.x와 다르게 매우 간단하게 정리되었습니다. eager execution이 본격적으로 사용되는 것처럼 위에서도 for-loop를 사용하여 데이터를 전달받을 수 있습니다.
기존의 tf 1.x에서는 iterator를 초기화 한 후 사용해야 하는 등 좀 더 복잡한 과정을 거쳤었습니다.
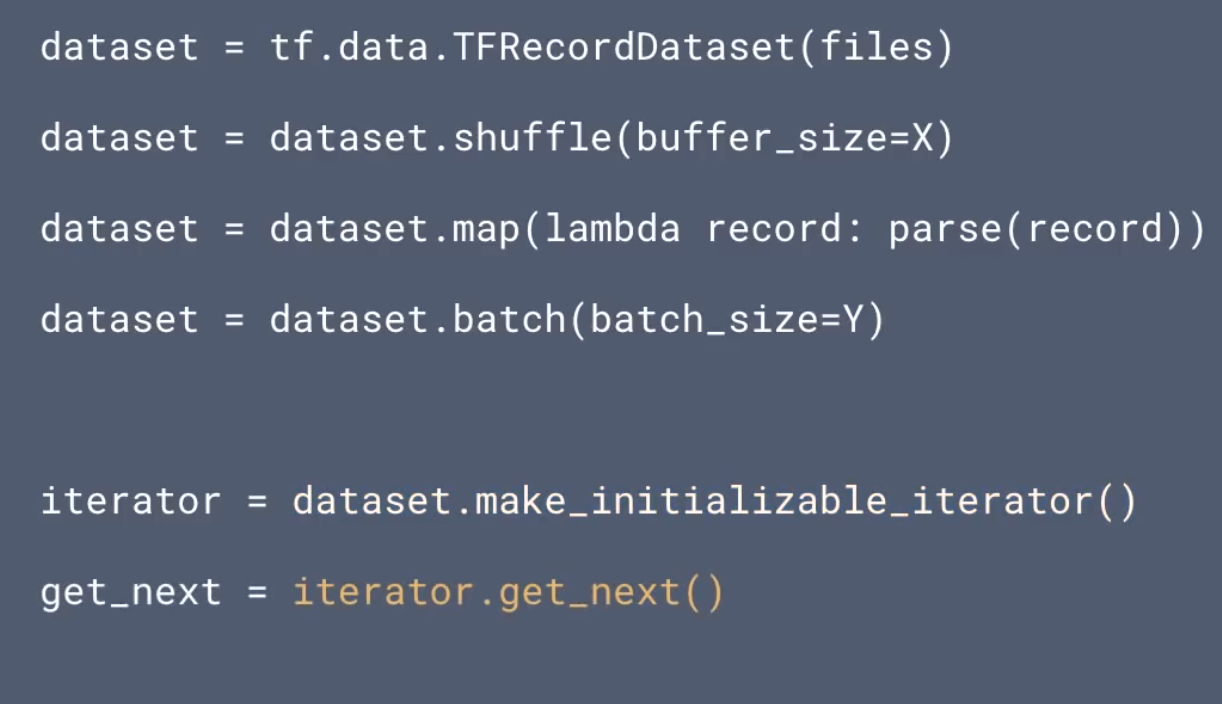
전체적으로는 다음의 프로세스를 가집니다. ‘tfrecord -> shuffle -> map -> batch’
C++의 요소를 넣어 performance 측면에서 이득을 취했고, 그 결과 다시 다음의 코드를 만나볼 수 있다.
dataset = tf.data.TFRecordDataset(files)
dataset = dataset.shuffle(buffer_size = X)
dataset = dataset.map(lambda record: parse(record), num_parallel_cells =...)
dataset = dataset.batch(batch_size = Y)
dataset = dataset.prefetch(buffer_size=...)
for element in datset:
...
supporting non-tensor types
텐서 타입이 아닌 타입을 다루기 위해서는 다음 이미지에 나오는 코드로 변환하여 tf.data를 사용할 수 있게 된다.

map이나 tensor_slice와 같은 함수는 기본적으로 tf.data Structure을 거쳐서 output 또는 input으로 반환되는 것을 볼 수 있다.
Static Optimizations
이 부분은 자세히 설명해주지는 않았지만, 대충 최적화를 위한 함수들이 있는 곳이라고 생각하면 될 것 같다. 다음과 같이 여러개의 함수가 존재한다.
- map + batch fusion
- map + filter fusion
- map + map fusion
- map parallelization
- map vectorization
- noop elimination
- shuffle + repeat fusion
- …
그리고 다음과 같이 사용한다.

(이 다음으로 C++ 측면에서 내부적으로 어떻게 흘러가는지 보여주지만 글에서는 생략한다.)
Dynamic optimization
======
아래 퀴즈에서 시작한다. 얼마나 많은 시간이 소요되겠는가?

모든 작업이 순차적으로 이루어지기 때문에 그렇다고 한다.
그렇다면 다음 작업은 얼마나 걸리겠는가에 대한 퀴즈를 또 한번 낸다.

첫 번째 질문과의 차이는 num_parallel_calls의 차이이다. background에서 서로 다른 커널에서 수행되는 것 같은데, 감이 잘 안온다. 아무튼 여러가지의 스레드를 만들어서 동시작업을 행한다고 생각하면 편하다.
하지만 맨 처음 element를 처리하는데 걸리는 시간은 첫 번째 문제와 같다는 것.
num_parallel_calls의 수가 늘어날 수록 output latency도 줄어든다. 하지만 그 수가 늘어난다고 해서 매우 많은 수의 thread를 만든다는 의미는 아니고, 여러 작업의 schedule을 동시에 처리해서 그 시간을 줄인다는 의미인 것 같다.